A Scholarly Contribution Graph
Since scientific literature is growing at a rapid rate
and researchers today are faced with this publications deluge, it is increasingly tedious,
if not practically impossible to keep up with the research progress even within one's own narrow discipline.
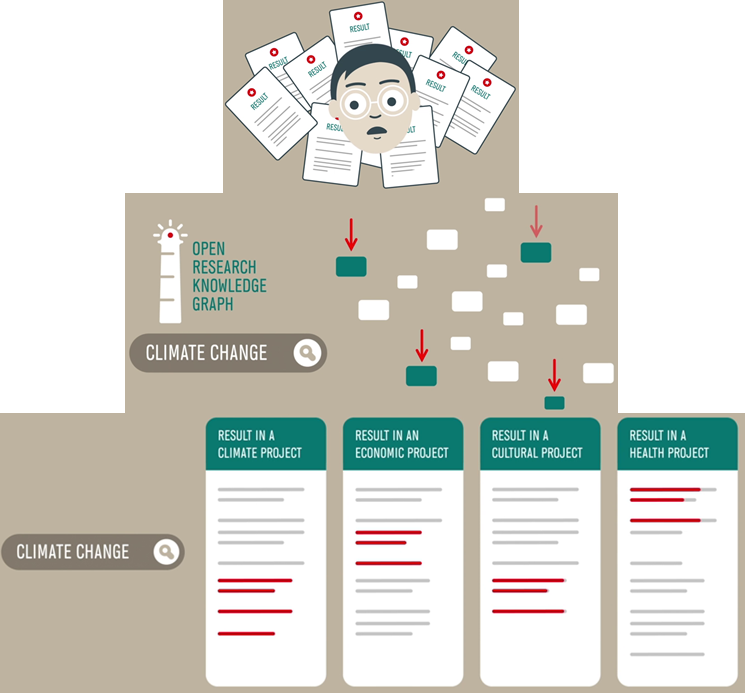
The Open Research Knowledge Graph (ORKG)
is posited as a solution to the problem of keeping track of research progress minus the cognitive overload
that reading dozens of full papers impose.
It aims to build a comprehensive knowledge graph that publishes the research contributions of scholarly publications per paper,
where the contributions are interconnected via the graph even across papers.
With the NLPContributionGraph Shared Task, we have formalized the building of such a scholarly contributions-focused graph over NLP scholarly articles
as an automated task.